

Online course 4: High Availability
Hi,
This is our 4th online course, we are using the shinken distributed capabilities to setup a truly high available setup :)
We already saw the installation of the 2.0 version in a linux box, but now we want to try the huge shinken distributed capabilities with a simple one: a high avaiability one.
In shinken this is managed like a disk RAID: you can define spare daemons that will take the job if a master one is down :)
You can follow this tutorial with this video:
(I cut the video at 6:15 because I give a looooong look at the logs there)
(You can also have a fr version of the video.
Our setup with 2 linux boxes
We will have 2 linux and we want a simple high availability setup, with box courses-a and courses-b. A will be the master one, and the B will be the spare one. We just installed shinken in the 2 boxes. Both got a valid dns entry :
root@courses-a$ cat /etc/hosts
[...]
192.168.56.104 courses-a
192.168.56.105 courses-b
root@courses-b$ cat /etc/hosts
[...]
192.168.56.104 courses-a
192.168.56.105 courses-b
First we will focus in the courses-a box. We will configure all daemons in the cfg of the master, and we will just copy all cfg files into the spare when we will be done.
We have to copy all our daemon master configurations, give them a new name and the good address (we will keep the default ports).
We want to have something like this :
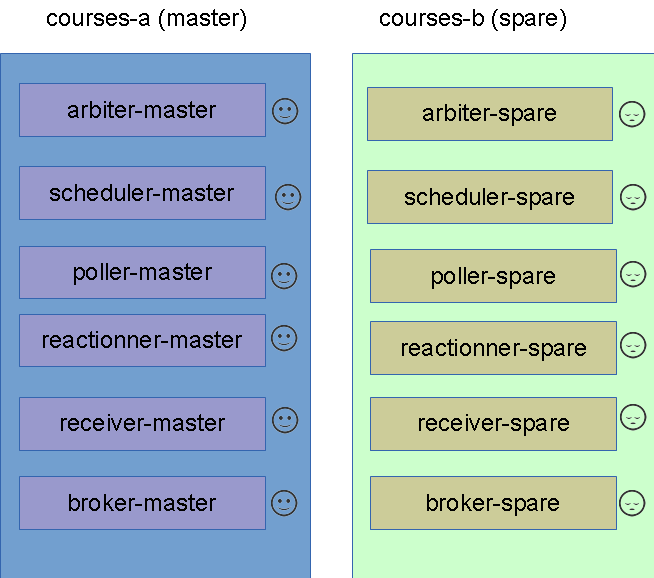
First let's look at the arbiter daemons, that is done to read and dispatch the configurations:
root@courses-a$ cp /etc/shinken/arbiters/arbiter-master.cfg /etc/shinken/arbiters/arbiter-spare.cfg
root@courses-a$ cat /etc/shinken/arbiters/arbiter-spare.cfg
define arbiter {
arbiter_name arbiter-spare
host_name courses-b ; CHANGE THIS if you have several Arbiters
address courses-b ; DNS name or IP
port 7770
spare 1 ; 1 = is a spare, 0 = is not a spare
modules CommandFile
use_ssl 0
}
We changed arbiter_name, host_name, address and spare properties. If the name is obvious, the others parameters are not :
host_name: specific to the arbiter, is is used by the arbiter daemon to find the arbiter object that match itshostnameaddress: where the arbiter master will have to connect to exchange dataspare: is this daemon a spare one or not? :)
The host_name parameter is important because the arbiter process will launch a hostname command to find where its launched, and then find a matching arbiter object.
We also need to edit the arbiter-master to be sure its address is the public ip and not localhost as by default.
root@courses-a$ cat /etc/shinken/arbiters/arbiter-master.cfg
define arbiter {
arbiter_name arbiter-master
host_name courses-a ; CHANGE THIS if you have several Arbiters
address courses-a ; DNS name or IP
port 7770
spare 0 ; 1 = is a spare, 0 = is not a spare
}
Then we need to do the same for all the other daemons now :)
The schedulers (scheduler the checks) :
root@courses-a$ cp /etc/shinken/schedulers/scheduler-master.cfg /etc/shinken/schedulers/scheduler-spare.cfg
root@courses-a$ vi /etc/shinken/schedulers/scheduler-spare.cfg
define scheduler {
scheduler_name scheduler-spare ; Just the name
address courses-b ; IP or DNS address of the daemon
port 7768 ; TCP port of the daemon
spare 1 ; 1 = is a spare, 0 = is not a spare
weight 1 ; Some schedulers can manage more hosts than others
timeout 3 ; Ping timeout
data_timeout 120 ; Data send timeout
max_check_attempts 3 ; If ping fails N or more, then the node is dead
check_interval 60 ; Ping node every N seconds
modules
realm All
skip_initial_broks 0
use_ssl 0
}
The pollers (launch the monitoring plugins).
root@courses-a$ cp /etc/shinken/pollers/poller-master.cfg /etc/shinken/pollers/poller-spare.cfg
root@courses-a$ vi /etc/shinken/pollers/poller-spare.cfg
define poller {
poller_name poller-master
address courses-b
port 7771
spare 1
manage_sub_realms 0 ; Does it take jobs from schedulers of sub-Realms?
min_workers 0 ; Starts with N processes (0 = 1 per CPU)
max_workers 0 ; No more than N processes (0 = 1 per CPU)
processes_by_worker 256 ; Each worker manages N checks
polling_interval 1 ; Get jobs from schedulers each N minutes
timeout 3 ; Ping timeout
data_timeout 120 ; Data send timeout
max_check_attempts 3 ; If ping fails N or more, then the node is dead
check_interval 60 ; Ping node every N seconds
modules
use_ssl 0
realm All
}
Same for the reactionners (launch the notifications and the event handlers):
root@courses-a$ cp /etc/shinken/reactionners/reactionner-master.cfg /etc/shinken/reactionners/reactionner-spare.cfg
root@courses-a$ vi /etc/shinken/reactionners/reactionner-spare.cfg
define reactionner {
reactionner_name reactionner-master
address courses-b
port 7769
spare 1
manage_sub_realms 0 ; Does it take jobs from schedulers of sub-Realms?
min_workers 1 ; Starts with N processes (0 = 1 per CPU)
max_workers 15 ; No more than N processes (0 = 1 per CPU)
polling_interval 1 ; Get jobs from schedulers each 1 second
timeout 3 ; Ping timeout
data_timeout 120 ; Data send timeout
max_check_attempts 3 ; If ping fails N or more, then the node is dead
check_interval 60 ; Ping node every N seconds
modules
use_ssl 0
realm All
}
Now for the brokers (grab events and data from the other daemons and export them):
root@courses-a$ cp /etc/shinken/brokers/broker-master.cfg /etc/shinken/brokers/broker-spare.cfg
root@courses-a$ vi /etc/shinken/brokers/broker-spare.cfg
define broker {
broker_name broker-master
address courses-b
port 7772
spare 1
manage_arbiters 1 ; Take data from Arbiter. There should be only one
manage_sub_realms 1 ; Does it take jobs from schedulers of sub-Realms?
timeout 3 ; Ping timeout
data_timeout 120 ; Data send timeout
max_check_attempts 3 ; If ping fails N or more, then the node is dead
check_interval 60 ; Ping node every N seconds
modules WebUI
use_ssl 0
realm All
}
And finaly the receivers (listen to external commands):
root@courses-a$ cp /etc/shinken/receivers/receiver-master.cfg /etc/shinken/receivers/receiver-spare.cfg
root@courses-a$ vi /etc/shinken/receivers/receiver-spare.cfg
define receiver {
receiver_name receiver-1
address courses-b
port 7773
spare 1
timeout 3 ; Ping timeout
data_timeout 120 ; Data send timeout
max_check_attempts 3 ; If ping fails N or more, then the node is dead
check_interval 60 ; Ping node every N seconds
modules
use_ssl 0
direct_routing 0 ; If enabled, it will directly send commands to the
; schedulers if it know about the hostname in the ; command.
realm All
}
Remember to also change the address entry of all master daemons, because the spare arbiter will need the LAN IP if it takes the lead and need to dispatch the configuration :)
Then you can copy the courses-a server configuration over the courses-b one. They must be the same.
shinken@courses-a$ scp -r /etc/shinken/* courses-b:/etc/shinken/
Then restart shinken on both servers:
root@courses-a$ /etc/init.d/shinken start
root@courses-b$ /etc/init.d/shinken start
The arbiter-master will talk each second to the arbiter-spare to say it is still alive, and so the spare must keep calm :)
If we look at the spare logs, all is clean :
root@courses-b$ cat /var/log/shinken/arbiterd.log
When we stop the courses-a daemons the arbiter-spare will take the configuration lead after max_check_attempts*check_interval seconds (from the arbiter-master configuration and will dispatch to the only available daemons, the spare ones.
root@courses-a$ /etc/init.d/shinken stop
[wait 3 min]
root@courses-b$ grep 'Dispatch OK' /var/log/shinken/arbiterd.log
We got something like this:
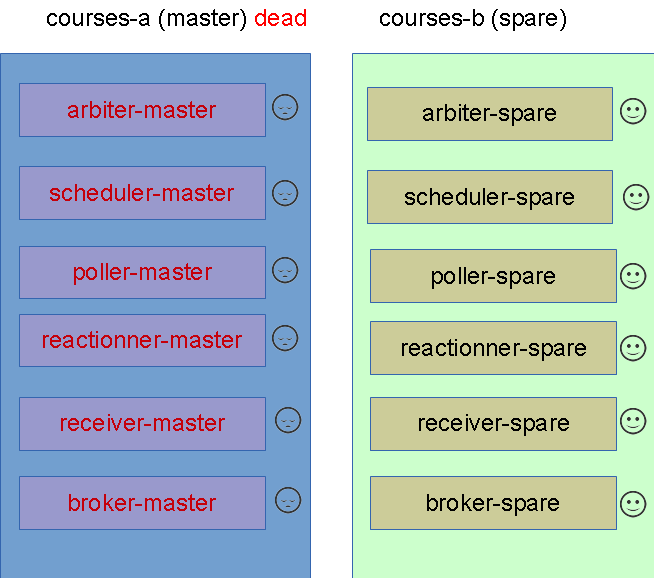
Issue with the PENDING states
But one problem we got when we switch to the spare daemons are that all checks are restarting from the PENDING state, but we don't wantto loose all our previous states. If we are using a flat file retention module for the schedulers like the pickle-retention-file-scheduler one the courses-b server won't be able to read the courses-a flat file of course. We must use a distributed retention module :)
Just look at what is available :
shinken@courses-a$ shinken search retention
pickle-retention-file-generic (naparuba) [module,arbiter,broker,retention] : Module for loading/saving retention data from a flat file (for arbiter & broker)
pickle-retention-file-scheduler (naparuba) [module,scheduler,retention] : Module for loading/saving retention data from a flat file (for scheduler)
retention-memcache (naparuba) [module,scheduler,retention,memcache] : Module for loading/saving retention data from a memcache server
retention-mongodb (naparuba) [module,scheduler,retention,nagios] : Module for loading/saving retention data from a mongodb cluster
retention-nagios (naparuba) [module,scheduler,retention,nagios] : Module for loading retention data from a nagios flat file. Useful for migration to Shinken from Nagios
retention-redis (naparuba) [module,scheduler,retention,redis] : Module for loading/saving retention data from a redis cluster
The one that is interesting us is the retention-mongodb one. Let's install it:
shinken@courses-a$ shinken install retention-mongodb
But beware, we also need to install it on the courses-b server !
shinken@courses-b$ shinken install retention-mongodb
This module will need some additionals python lib, on both servers of course :
root@courses-a$ apt-get install python-pymongo python-gridfs
root@courses-b$ apt-get install python-pymongo python-gridfs
We will have such architecture:
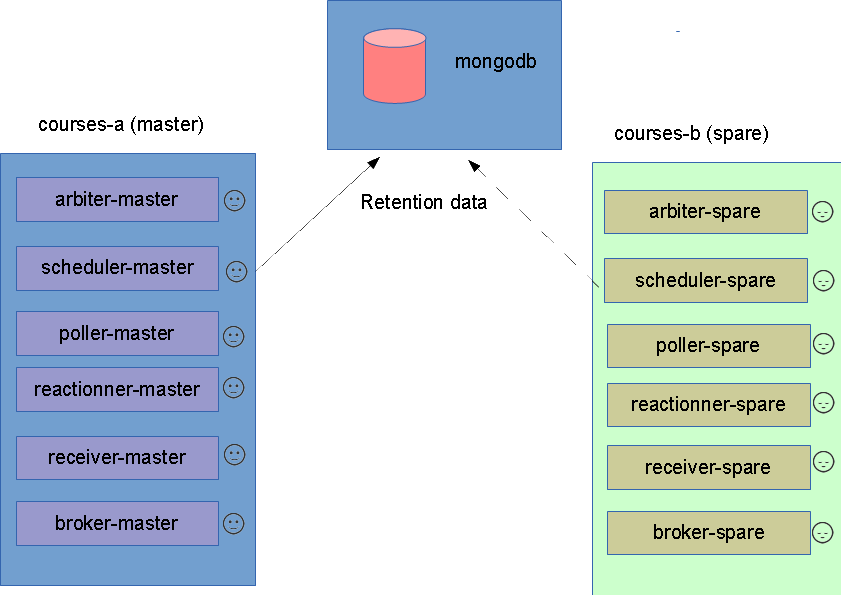
We will need a mongodb server. I'll install it on another server. You can easily setup it by folowing the documentation. It will be on te 192.168.56.103 server for me.
The module configuration is /etc/shinken/modules/retention-mongodb.cfg:
root@courses-a$ cat /etc/shinken/modules/retention-mongodb.cfg
define module {
module_name MongodbRetention
module_type mongodb_retention
uri mongodb://192.168.56.103/?safe=false
database shinken
}
Note that you need to edit the uri with your server address :)
Then we can just enable the module on both schedulers:
root@courses-a$ /etc/shinken/schedulers/scheduler-master.cfg
[..]
modules MongodbRetention
[...]
root@courses-a$ /etc/shinken/schedulers/scheduler-spare.cfg
[..]
modules MongodbRetention
[...]
Then copy your configuration from courses-a to courses-b with the previous scp command.
shinken@courses-a$ scp -r /etc/shinken/* courses-b:/etc/shinken/
Then you can restart boths servers and try to stop the master daemons one time again. This time the retention data will be ok :)
The next course
The next course will be about a focus on the enterprise edition, the next one will be about the shinken daemons and what they are done for :)




comments powered by Disqus


